在Nop平台中只需要增加imp.xml导入模型即可实现对存储在Excel中的复杂业务对象的解析,具体imp模型的定义参见imp.xdef
基本原理
对于普通字段,按照左侧是label,右侧是值来解析
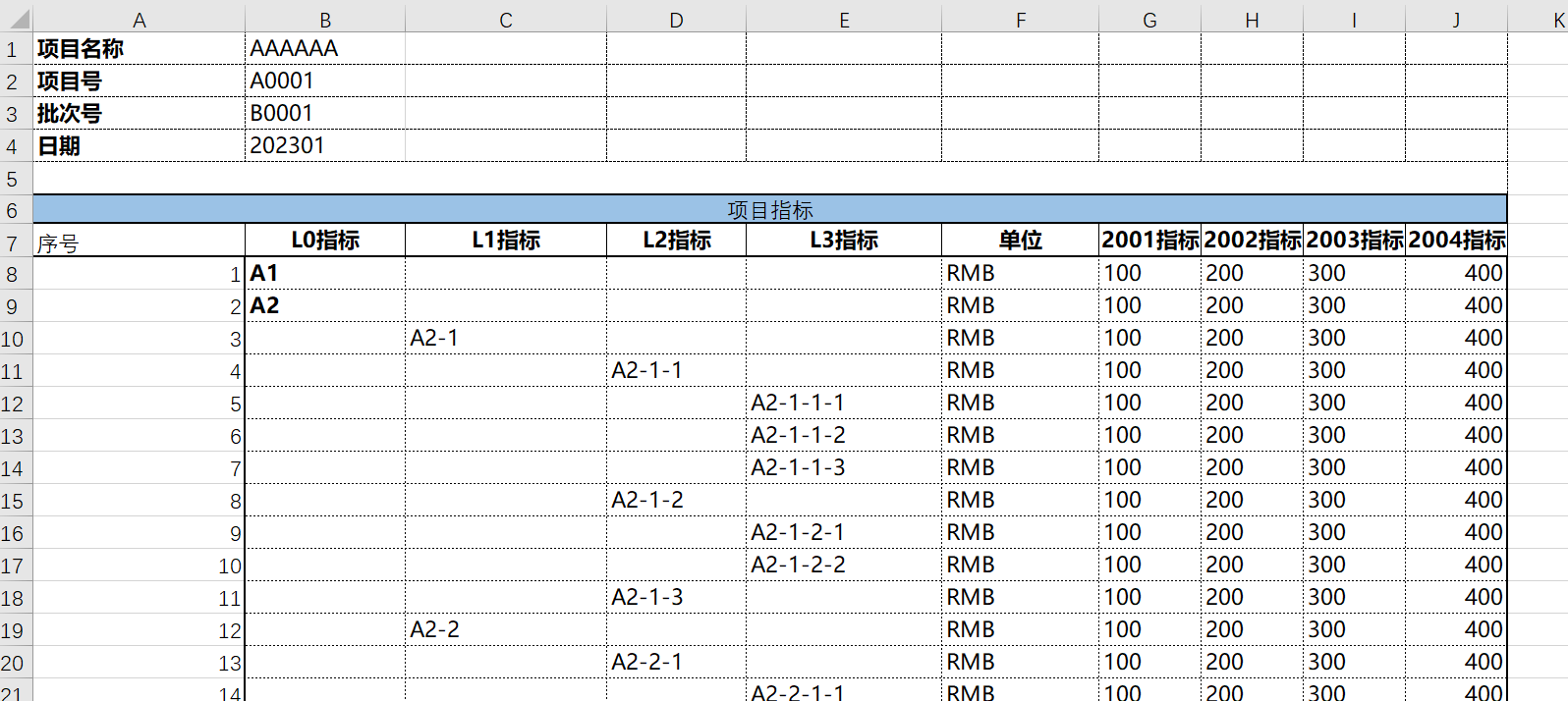
对于列表字段,可以按照上面是label,下方是列表来解析
列表的第一列必须是数字列,不要求编号唯一,也不要求编号列在字段列表中定义。它仅仅被用于确定列表行的范围。
关键是在整体结构上能够明确的识别出父子关系。父字段必须覆盖子字段的范围。这样才能实现自动解析。
label可以对应于field的displayName或者name,两者都可以
字段的前后顺序不影响解析。在imp.xml中定义的field是全集,实际的模板中可以只使用部分字段。
但是标记为mandatory的字段必须在模板中存在,否则解析后发现对应字段值为空,会抛出异常。
配置说明 如何解析列表
sheet或者field上标注list=true,表示将会解析得到一个列表
列表的第一列必须是数字列,不要求编号唯一,也不要求编号列在字段列表中定义。它仅仅被用于确定列表行的范围。
如何解析一组sheet得到一个值 <sheet name ="ss" namePattern =".*" multiple ="true" multipleAsMap ="true" field ="ss" > </sheet >
namePattern指定一个正则表达式,它描述如何匹配对应的sheet
multiple=true表示会匹配到多个sheet
multipleAsMap=true表示匹配到的多个sheet解析后,会按照sheetName汇总成一个Map。如果不指定这个属性或者设置为false,则多个sheet的解析结果会合并为一个List
使用导入模板来实现导出
首先制作一个空的导入模板,即把导入数据删除,保留列表数据的序号列。具体样例参考template.orm.xlsx
在imp.xml文件中通过templatePath属性来指向导入模板
<imp x:schema ="/nop/schema/excel/imp.xdef" xmlns:x ="/nop/schema/xdsl.xdef" xmlns:c ="c" xmlns:xpt ="xpt" templatePath ="template.orm.xlsx" > </imp >
ExcelReportHelper中提供了根据导入的业务数据自动生成html或者xlsx文件的方法。
Object bean = ExcelHelper .loadXlsxObject ("/nop/test/imp/test5.imp.xml" , resource);String html = ExcelReportHelper .getHtmlForXlsxObject (impModelPath, bean, scope);ExcelReportHelper .saveXlsxObject (impModelPath, resource, bean);
在imp模型的帮助下,Excel可以被看作是Java对象的一种序列化形式,类似于JSON和Java对象之间的自动双向转换,我们可以实现Excel和Java对象之间的自动双向转换。
具体示例参见TestImportExcelModel.java
动态确定需要导入的列 示例配置test3.imp.xml ,TestParseTreeTable.java
通过fieldDecider可以动态确定数据列所对应的解析配置。例如 2002指标、2003指标等列是动态变化的,我们希望解析这些列并把它们转换为一个列表属性。
<field name ="columns" displayName ="项目指标" list ="true" > <fields > <field name ="name" displayName ="指标" mandatory ="true" /> <field name ="indexValue" displayName ="X年指标" virtual ="true" > <schema stdDomain ="int" /> <valueExpr > </valueExpr > <xpt:labelExpandExpr > </xpt:labelExpandExpr > <xpt:labelValueExpr > </xpt:labelValueExpr > <xpt:valueExpr > </xpt:valueExpr > </field > </fields > <fieldDecider > </fieldDecider > </field >
virtual=true表示是虚拟字段。导入时只会执行字段的valueExpr,但并不会把返回的value设置到record的属性上。
在valueExpr执行的时候可以通过fieldLabel来引用字段的标题,通过value引用从单元格中解析得到的值,通过cell引用当前单元格
xpt:labelExpandExpr等以xpt:为前缀的标签在数据导出的时候使用。xpt:labelExpandExpr用于动态生成表格列
xpt:valueExpr返回动态生成的列所对应的单元格的值。cell.rp.ev相当于 cell.rowParent.expandValue用于获取行父格的展开值,而
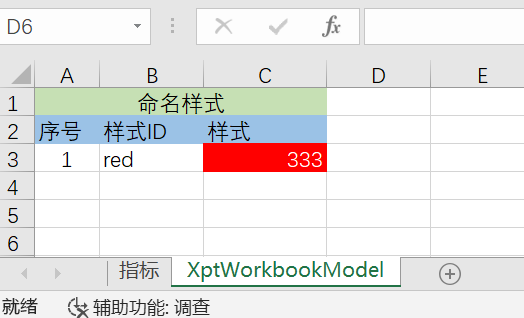
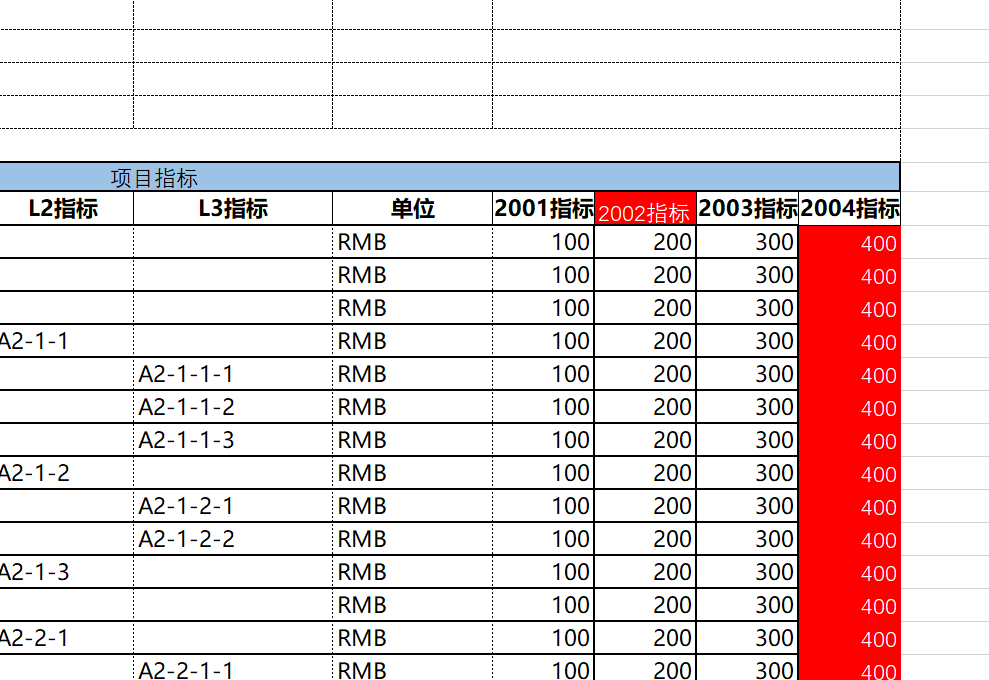
动态设置单元格样式 导出数据的时候可以增加动态样式:当单元格的值满足某些条件的时候采用指定的样式来显示。例如当单元格的值大于300的时候,将单元格背景设置为红色。
<field > <xpt:labelStyleIdExpr > </xpt:labelStyleIdExpr > <xpt:styleIdExpr > </xpt:styleIdExpr > </field >
在数据模板中需要增加XptWorkbookModel这个Sheet页,在其中定义命名样式。
实际导出的结果为
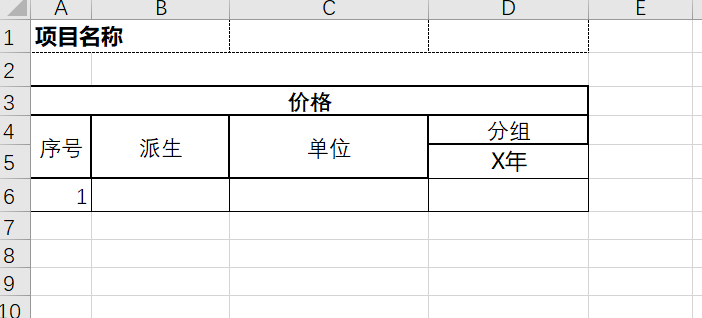
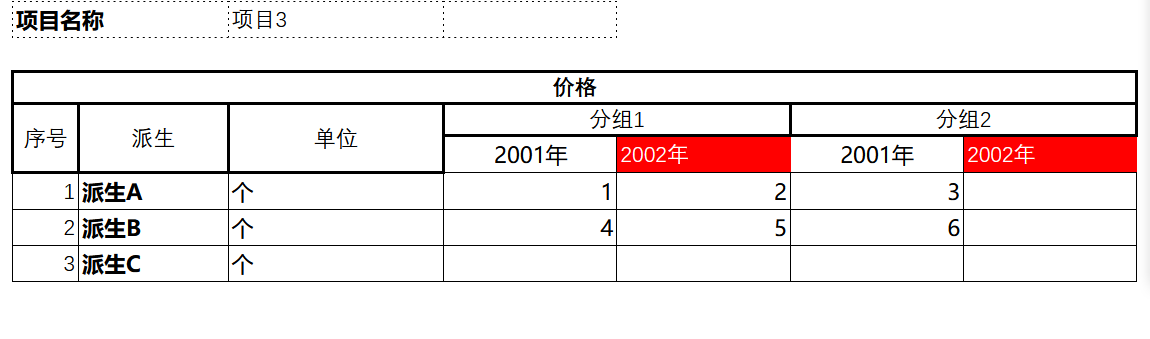
支持复合表头 导入数据的时候可以支持多级表头(目前只支持两级)
导出结果为
在imp.xml导入模型中进行配置时,只考虑匹配最下层的字段,分组字段不会直接参与匹配。
在field配置上增加groupField配置,它对应于另一个field配置,在其中可以配置xpt:labelExpandExpr等导出配置。
<fields > <field name ="indexValue" displayName ="X年" virtual ="true" groupField ="group" > <schema stdDomain ="int" /> <valueExpr > </valueExpr > <xpt:labelExpandExpr > </xpt:labelExpandExpr > <xpt:labelValueExpr > </xpt:labelValueExpr > <xpt:valueExpr > </xpt:valueExpr > <xpt:labelStyleIdExpr > </xpt:labelStyleIdExpr > <xpt:styleIdExpr > </xpt:styleIdExpr > </field > <field name ="group" displayName ="group" > <schema stdDomain ="string" /> <xpt:labelExpandExpr > </xpt:labelExpandExpr > </field > </fields >
在导入具体数据单元格的时候,可以通过labelData变量(LabelData类型)访问到对应的labelCell和groupCell, 以及对应的field配置等。
与Spring框架集成 如果要使用Nop平台的Excel导入导出功能,只需要在pom文件中引入如下模块
<dependencies > <dependency > <groupId > io.github.entropy-cloud</groupId > <artifactId > nop-spring-core-starter</artifactId > </dependency > <dependency > <groupId > io.github.entropy-cloud</groupId > <artifactId > nop-report-core</artifactId > </dependency > </dependencies >
具体示例项目参见 nop-spring-report-demo