GPT用于复杂代码生产所需要满足的必要条件
现在很多人都在尝试用GPT直接生成代码,试图通过自然语言指导GPT完成传统的编码工作。但是,几乎没有人去真正认真的考虑一下生成的代码如何长期维护的问题。
基于可逆计算理论的基本概念,我们可以进行如下推理:
如果一段复杂的业务逻辑代码要能够长期稳定运行,那么肯定不可能是每次需求变化都重新生成代码。我们必须要以受控的差量化的形式对原有的逻辑进行修正,所以我们必须要定义Delta差量空间,而且必须要保证在这个空间中能够通过程序自动进行差量合并运算。更进一步的推理,如果我们要保证对一个复杂系统的差量描述的稳定性,那么它必然是要定义在具有业务含义的领域模型空间,而不能定义在通用程序语言空间。通用程序语言空间过大,而且与需求空间不是对齐的关系,一个很小的需求变化可能导致通用程序语言空间中大量的变动,从而影响到逻辑表达的稳定性。
考虑到自然语言天生的歧义性,复杂业务逻辑的稳定载体不应该是自然语言。可以想象一下,即使今天的自然语言描述在当前的语境下是无歧义的,随着社会环境的变迁,人们使用的词语含义的漂移,同样的自然语言描述在未来的语境下也可能会产生不同的解读。为了稳定、精确的表达业务逻辑,保证绝对可重复的按照指定语义执行,我们需要使用人类智能最近100年才达到的光辉顶点;形式语言。为了保证GPT自动生成的形式语言逻辑可以被人们理解并快速进行验证和检查,它应该提供一种与业务需求的复杂度相匹配的、可以使用工具自动验证、并可以从中反向抽取信息用于其他用途的描述式语言:领域特定语言(DSL)。
程序代码中沉淀了大量业务知识,但是此前的编程技术往往将这种知识禁锢在某种技术实现中,我们没有通用的技术手段反向进行信息提取。即使是可以使用GPT去理解一段现成的代码并生成对它的自然语言解释,我们也难以生成一段程序可以准确无误的将我们需要获取的知识从系统源码中反向提取出来。GPT生成的代码解释仅仅能起到一些参考作用,它随时可能因为幻觉而胡说八道。但是,如果我们是使用GPT来构建一个新的系统,为什么不从一开始就使用一种支持可逆分析的结构表达方式?
如果GPT不是通过简单的问答方式完成任务,而是可以调用外部插件、自行设计比较复杂的执行计划,那么无论从安全性角度考虑,还是从与外部交互的稳定性角度考虑,我们都需要限制GPT发出的指令必须限制在我们预先设定的语义空间中。
有些程序员可能并不重视理论层面的分析,认为针对AI大模型的Prompt工程就是一个实践经验累积的问题。我不同意这种观点。实际上,根据上面可逆计算理论的分析,我们可以很自然的得到将GPT作为严肃的软件生产工具所需要满足的必要条件:
GPT的输入输出应该是差量化的DSL(领域语言)描述。
建立在统一元模型基础之上的DSL森林
很多人相信GPT可以理解复杂的业务逻辑描述并生成准确无误的通用代码实现,那GPT为什么不能掌握结构更简单、语义定义更清晰的DSL语言?一个常见的误解是,DSL语言采用自制的小众语法,大语言模型没有足够的训练语料,无法掌握它的语法。但实际上,DSL真正重要的是它所建立的领域语义空间,它会使用领域中专有的名词,非常精炼的表达相关的业务知识,并且可以很自然的映射到用户的需求描述。比如为了描述用户的审批流程,我们只需要使用流程、步骤、动作、审批人等少数概念,DSL中使用的每个Token都具有业务语义,而不是因为某种技术限制而加入的。反之,如果要使用通用语言代码去定义,则必然会涉及到导入依赖包、声明变量作用域等一系列与业务无关的、因为程序语言语法限制而产生的细节问题。
如果只关注于DSL的语义,我们完全可以采用通用的XML或者JSON语法作为DSL的通用语法。简单的说,DSL可以采用AST语法树的形式来定义。这种做法类似于LISP语言的S表达式,只不过我们可以采用XML标签这种更加易读的表示方式。多种不同的表示方式之间是可以进行可逆转换的。比如,Nop平台中定义了XML和JSON格式之间的多种可逆转换的方式,本质上用JSON和XML都可以表示同一个DSL。
采用了统一的表示语法之后,不同的DSL就可以使用统一的元模型来进行约束(类似Json Schema),并进而构成一个DSL森林。DSL森林借助于统一的元模型可以实现语义上的一致性理解,并支持多个DSL之间的无缝嵌入。
很多程序员有一个传统上的印象,认为设计新的DSL需要自行编写解析器、编译器,而且还需要自己维护IDE插件,工作量浩大。但是在Nop平台中,只需要定义XDef元模型,就可以自动得到解析器、验证器、IDE语法提示功能,并且可以直接在IDEA中设置断点进行单步调试!Nop平台还可以根据XDef元模型定义自动实现领域对象与Excel模板文件之间的双向转换(将Excel文档转换为DSL描述,或者根据DSL描述导出Excel文档),可以自动生成可视化设计器等。Nop平台提供了所谓领域语言工作台(Domain Language Workbench)的概念,可以快速开发并扩展DSL语言。它的这一设计目标类似于JetBrains公司的MPS产品,但是Nop平台建立在可逆计算理论的概念基础之上,它的技术路线更加简洁、明确,复杂度远远小于MPS,另一方面在灵活性和可扩展性方面又大大的超越MPS。
为什么XML是一种合适的DSL语法载体?
很多程序员并没有亲自设计过XML格式的DSL语言,只是听业界的前辈讲过上古时代的XML是如何被后起之秀淘汰的传说,就由此形成了一种刻板印象,认为XML过于冗长,只能用于机器之间传递信息,并不适合于人机交互。但是,这是一种错误的偏见,源于XML原教旨主义对于XML错误的使用方式,以及一系列XML国际规范对错误使用方式的推波助澜。
很多人一想到用XML来表达逻辑,浮上心头的刻板印象可能是
|
但是实际上我们完全可以采用如下XML格式
|
如果要表达arg1的参数值类型是整数类型,而不是字符串类型,则可以对XML语法进行扩展,允许直接使用数字作为属性值。也可以类似Vue框架,通过补充特定的前缀信息来区别是否字符串,例如规定@:前缀表示后面的值满足JSON语法规范,可以按照JSON格式进行解析。
|
在Nop平台中,我们规定了JSON和XML之间的双向转换规则。例如对于如下AMIS页面描述:
|
对应的XML格式为
|
实际上XML语法看起来要更加紧凑直观。
这里使用的是无元模型约束的JSON-XML转换,所以需要使用j:list来标记数组元素,并用@:前缀来表示非字符串值。如果XML文件具有XDef元模型定义,就不需要这些额外的标注信息了。
使用XML相对于JSON格式的另外一个好处是它可以很容易的引入XML扩展标签来用于代码生成,代码的表示形式和代码生成的结果形式都是XML格式,这在Lisp语言中被称作是同像性。目前JSON格式缺乏一种同像的代码生成方式。
|
关于XML和JSON的等价性,进一步的讨论可以参见 XML、JSON和函数AST的等价性
AI需要理解元模型
AI大模型之所以引起轰动,本质上在于它表现出了超越简单模式记忆的复杂的逻辑推理能力。在这种能力的加持下,AI大模型学习DSL语言应该完全不需要大量的程序语料,只需要告诉它这个语言内在的结构约束规律就可以了。
元模型和元语言的发现是近100年来数学领域中最具革命性的发现之一。元模型和元语言在数学领域具有特殊的重要地位,范畴论的发展与模型论、元语言的研究息息相关。在程序开发领域,我们应该可以通过元模型向AI大模型精确的传递DSL语法结构知识以及局部的语义知识,具体来说所谓的元模型基本可以看作是一种类似JSON Schema的模式定义。
在Nop平台中,我们强调元模型与具体模型对象之间的同态关系。也就是说,Schema的形式应该和数据自身的结构形式基本一致,而不是像XML Schema那样把树状结构的领域结构拆分为大量的对象-属性关系,用完全不同的语法形式去表达。例如
|
基本上XDef就是把具体的值替换为stdDomain定义,同时对于列表元素只保留唯一的一个条目。
stdDomain类似于类型声明,但是它可以由用户自定义的扩展,所有的stdDomain在一个字典表中维护,可以实现对于字段值施加局部的语义约束。例如,class-name表示必须满足java类名的格式要求,并不允许所有的字符串。在stdDomain前可以添加感叹号,表示该属性值不能为空。
目前的大模型都是通过填空的方式训练的,所以采用这种同态设计方式也便于大模型快速掌握元模型。现在大模型应用中给定少量样本的情况下也可以反向猜测得到对应的Schema类型约束,但是这种猜测肯定是不准确的,比如说我们很难通过样本告诉大模型,某些格式的字符串是不合法的,比如不允许包含-作为连接符等。通过元模型可以快速高效的向大模型传递领域知识。
所以我认为,大模型的训练过程中应该有意识的加强对于元模型的训练,元模型应该和普通的模型有所区分,值得付出额外的努力提高大模型对于元模型的精确掌握程度。
具体使用元模型与GPT交互的尝试可以参见我的文章 GPT驱动低代码平台生产完整应用的已验证策略
Nop平台与GPT结合的具体策略
Nop平台与GPT沟通的策略如下:
- 通过当前所使用DSL的xdef元模型帮助GPT更快、更精确的理解DSL结构
- 通过可逆计算的差量合并规则,指导GPT直接返回差量描述
- 将返回差量合并到当前模型上,成为新的当前模型,在此基础上可以无限次与GPT沟通。
- 对于复杂的逻辑推理往往无法通过单一的DSL一步到位的解决问题,此时我们可以通过多个DSL来建立一个差量流水线,将问题分解为几个步骤来解决。
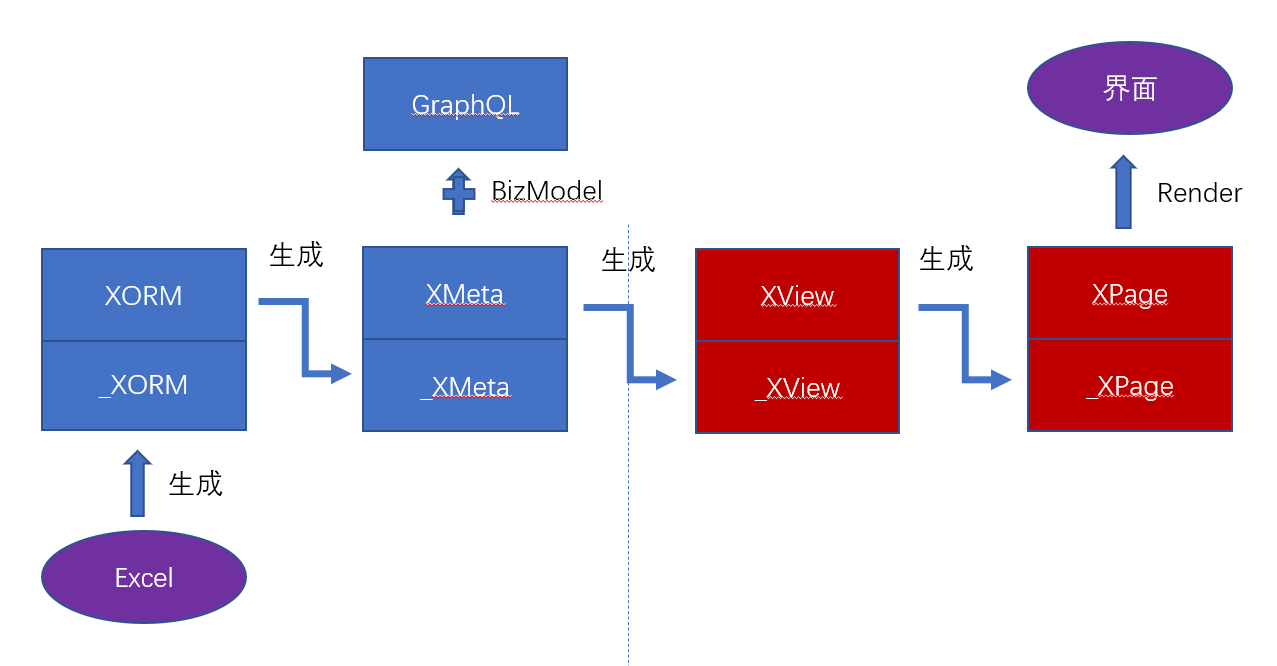
基于Nop平台提供的DSL支持,AI和人工可以采用如下的相互配合方式:
AI按照需求规格产生顶层的DSL
通过人工编写的代码生成器将DSL展开为下一层次的DSL
人工可以使用Delta定制方式对AI生成的DSL进行细化调整
最细节处可以让AI根据局部知识再进行细化
简单的说起来相当于是1. AI产生粗加工结果 2. 人工细化 3. AI抛光
现在很多程序员设想的AI代码生成都是生成接口、类、属性等软件中常用的组成成分。但是Nop平台中的做法与此完全不同。正如我不断强调的观点,类-属性的抽象是我们受底层实现技术的限制所形成的结果,它与领域内部结构之间的关系并不是完全对应的,比如我反复强调的领域结构坐标的概念映射到类型层面之后会出现缺失,导致无法精确的进行差量化修正。Nop平台中的DSL是面向Tree结构的,可以一次性的产出一整颗逻辑树。
有些人想到要对此前生成的代码结构进行微调,那么是否可以利用AI模型生成一系列的API调用,通过这些API来调整模型?例如通过生成API来从数据模型中删除phone3字段。
|
如果对比一下Nop平台中的Delta合并算子,我们就可以知道为什么这种API的方式是一种不优化的方案。
|
Nop的方案具有如下优势:
多个Delta修改可以合并成一个结果,并且在合并的过程中可以进行简化,抛弃重复修改的部分。而使用API的方式本质是把修改动作作为Delta来使用,但是多个动作无法被自动合并、简化。如果不在脑海中逐个执行这些动作,我们无法理解最终系统会被修改成什么样。这也就是可逆计算理论一直强调的,Delta应该可以被独立被理解、独立被定义,并且Delta应该满足结合律,可以进行局部化简。
领域模型的Delta定义可以被程序自动分析,反向抽取出其中的信息。而如果采用API的方式来实现Delta,我们就没有很简单的工具可以分析Delta的具体组成,在不应用Delta之前无法精确知道它的影响范围等。这种逆向信息抽取的能力也是可逆计算理论所反复强调的内容。
Delta修改之所以能够应用到基础模型上在于我们可以精确的定义变化发生的位置,如实体模型的字段集合中的名称为phone3的字段处,这个位置定义应该是有着明确业务含义,且具有唯一性的某种路径定义,而MyEntity模型文件中的第10行到第20行这样的定位描述方式其实是不稳定、不明确的。Nop平台的Delta定制方案是对领域模型坐标系的精确利用,而API调用的方式则将定位坐标这一概念深深的隐藏在函数的调用链中。GPT生成时完全可能使用某些临时的定位手段,而错过领域坐标系中最有效的直接定位手段。
实际上,基于可逆计算理论的指导,主动从元模型、可逆、差量化的角度去重新审视编程中的具体实践方案,我们可以得到很多新的认知,并找到进一步改进的方向。
从可逆计算的角度看Prompt
一些硬核的prompt设计可以很自然的从可逆计算理论的角度进行解释,比如HuggingGPT中的TaskPlan:
|
这个提示词的形式非常接近于XDef元模型定义。而HuggingGPT的运行方式正是让GPT返回满足元模型要求的DSL语句。
微软提出的guidance项目采用如下格式的prompt:
|
显然,如果引入一种规范化、系统化的树状结构表示方法,可以说机器省心,我们也省心。
基于可逆计算理论设计的低代码平台NopPlatform已开源: